Image courtesy of Adobe Stock.
Image courtesy of Adobe Stock.
Content enrichment is the process of applying modern content processing techniques such as machine learning, artificial intelligence, and language processing to automatically extract meaningful information from your documents. The ability to draw valuable insights from content allows organizations to drive better eDiscovery results, information management, and business decision-making.
This article will provide an overview of three major content enrichment features and demonstrate how they can be practically utilized with Collabspace to bring value to the way you work. We’ll cover:
1. Named Entity Recognition
2. Object Detection
3. Sentiment Analysis
Curious to learn more? We've got a free, in-depth white paper defining Content Enrichment, six of its features and how to apply to your organization to improve your work tasks and improve business functions. Download it below!
Using the right tool
To reap the benefits of content enrichment, it is important to use the right tool. Moving a step beyond on-premise capabilities, storing content in the cloud can give users access to content enrichment features. We'd recommend Collabspace, which has introduced named entity recognition, object detection, and sentiment analysis for DISCOVERY and CONTINUUM users.
How does it work? These features are processed on-demand with Collabspace's high-performance data lake, unlocking new value from existing content to reach previously unavailable data. Extracted data will supply your documents with valuable metadata by helping categorize, sort, and locate relevant information within Collabspace. Now, let's get into each feature...
1. Named Entity Recognition
Named entity recognition is an information extraction process that uses machine learning to automatically identify entities in unstructured data, such as images, videos, and scanned pdfs. An entity is a word or phrase that matches a pre-defined type such as person, place, time, etc. A list of entity types is shown below as example:
|
Type |
Description |
|
PERSON |
People, including fictional. |
|
NORP |
Nationalities or religious or political groups. |
|
FAC |
Buildings, airports, highways, bridges, etc. |
|
ORG |
Companies, agencies, institutions, etc. |
|
GPE |
Countries, cities, states |
|
LOC |
Non-GPE locations, mountain ranges, bodies of water. |
Entity extraction is a powerful tool that revolutionizes the process of finding and grouping all content related to a specific person, location, event, organization, or any other entity label from the given list!
In addition, having automatically generated entities is beneficial for summarizing a document's contents. Rather than scrolling through pages of a document to see if it has the information you are looking for, you can now simply look through the list of entities to see if the document is relevant.
How to use named entity extraction in Collabspace
Entity recognition brings in a new wave of metadata for your documents, expanding your toolbox for searching, sorting, and categorizing data containing entities.
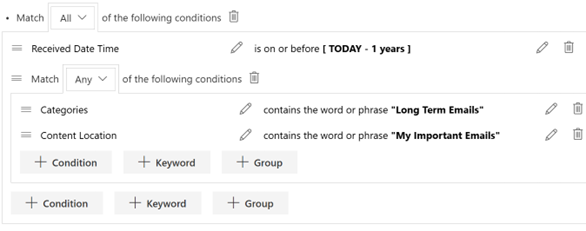
For example, imagine a scenario where your company must find and present all information that references a specific person, say William Shakes. If you are storing information and searching in Collabspace, the platform will recognize and identify William Shakes as a person so the document will appear in a search (or auto-categorization) for "people named William Shakes."
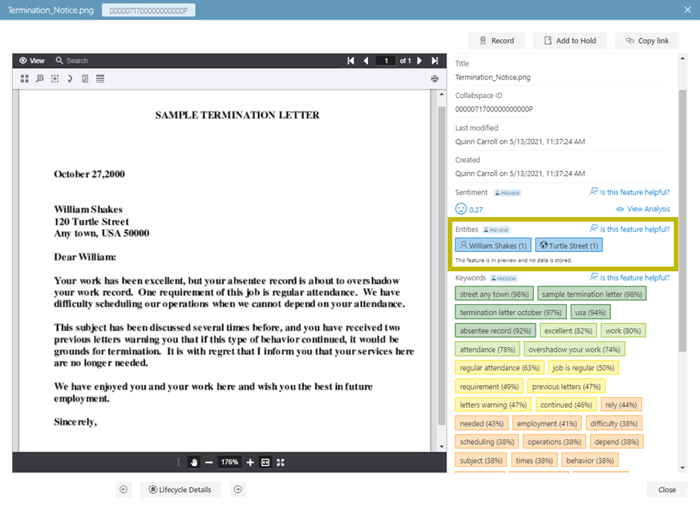
Searching is not the only application of the named entity recognition feature. Say the document above is in the search results for "location called Turtle Street." If you needed to present this document to a third party, you might not want to disclose William Shakes' name, as it is personally identifiable information. Since William Shakes is identified as a person, this automates the otherwise time-consuming process of figuring out what needs redacting before presenting the document to the third party.
2. Object Detection
While entity recognition can extract metadata from a text in various document types, we need a tool that can recognize non-text elements within these documents. This is where the object detection feature can help.
Using a machine learning model to identify named objects within images, object detection automatically provides you with image keywords to categorize and sort through heaps of image files based on the objects within. The extracted keywords are perfect for managing cluttered and unsorted image files stored in your Collabspace.
This feature unveils your dark data by adding descriptive metadata to image files that otherwise have few identifying features.
Object identification can also help identify personal information that may need redaction before disclosing it to a third party. For example, all instances of a person may be personally identifiable information. The object detection feature would allow you to find all images that include a person as an image keyword, identifying documents that may need redaction. This automates an otherwise tedious process, saving valuable time for your company.
These image keywords provide helpful metadata that can locate image files by the objects within the images.
3. Sentiment Analysis
The two features we have looked at so far have been extracting information from the document's objective elements. With sentiment analysis, we get the chance to analyze the text's subjective material through word choice to determine the writer's tone.
By simply determining whether documents in your Collabspace are positive or negative, sentiment analysis can add a lot of value to your business. Suppose you have customer reviews in your Collabspace. In that case, you can now quantify customer sentiment concerning a particular product or service, getting a better understanding of how you are connecting with your customers.
Sentiment analysis is also a valuable feature when it comes to monitoring internal communication. Keeping the workplace positive is vital for productivity; thus, checking the sentiment of internal communications is a helpful tool. Searching for documents based on this sentiment value can also come in handy when you need to access only positive or negative communication instances.
How to use sentiment analysis in Collabspace
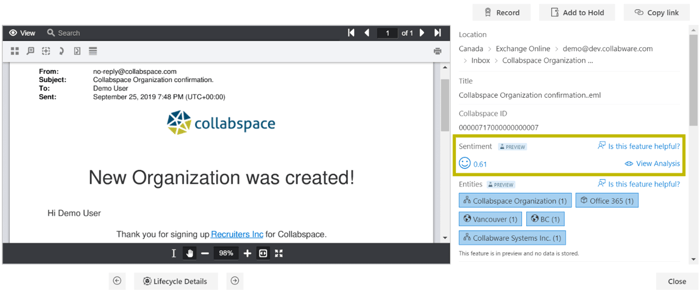
Whether checking the sentiment of customer reviews or internal communication, the Collabspace sentiment analysis feature will produce a single value between -1 and 1 that specifies the text's attitude according to the graphic below.

In the example below, the text is classified as positive, having a sentiment value of 0.61 (hence the smiley face).
Without cluttering search results, these content enrichment features harness artificial intelligence to provide richer metadata for auto-categorizing, searching, and summarizing both structured and unstructured data.
We have a full length white paper on content enrichment, six features and how it can be applied across your organization. Download it for free:


To learn more about content enrichment in Collabspace, we've also included a free, on-demand webinar on this topic below. Feel free to contact us with any questions or to book a demo and see how you can utilize these features to bring additional valuable data insights to your organization.

Loved what you read, and want to learn more? Check out our white paper on why and how to apply artificial intelligence to information management, and subscribe to the Collabware blog to keep up with our latest and greatest!
*It is important to note that these features are still in preview mode, so searching for documents based on these outputs is not yet possible in Collabspace.