This article has been written in collaboration with Justin Head and edited by Nadia Lepak.

Image shows employee at desk, working on laptop. Photo by Karolina Grabowska via Pexels.:
Us in the RIM community love process, right? Without it, we would live in total chaos: our records would go missing, the risk meter would be crimson red, and the overall stress would be too much to bear. As such, we strive to create best practices and policies for those who are creating records: our beloved end users.
A critical part of these records management best practices is the metadata capture. The early history of electronic records showed us that to efficiently locate a file, we needed to capture terms of that data, i.e., the metadata. For this task, most organizations use manual processes that rely heavily on end user interaction. The result? Well... simply put, there's a gap between reality and our dreams.
Let’s talk about why, and a more optimal alternative for capturing your metadata. And if you'd like the full slide deck from the presentation myself and my colleague delivered on this topic, you can download that for free, below!
This article will cover...
- the traditional model of metadata capture,
- 5 reasons manual metadata should be a practice of the past,
- the metadata capture process with go-to technologies such as SharePoint,
- and an alternative solution for optimized metadata capture.
Traditional manual metadata capture
The traditional model for capturing metadata relies on users to manually populate multiple fields with metadata when declaring a record so their ECM of choice (pick your poison) can easily recall these documents when needed. Most end users can relate to the pain of having to remember specific naming conventions or needing capture information over and over again, from document to document. Sounds time consuming and tedious, right?
It is. We’ve compiled a list of 5 reasons behind why we’re rooting for manual metadata capture to be a practice of the past:
1. Time-consuming
Going about this process manually takes time and effort. And the amount of effort spent trying to build out the perfect information architecture only to have end users bypass it can be frustrating. Why do they bypass it? See the next two points…
2. Tedious
Once again: inputting metadata into each field, record by record, is not only a time-consuming task but also monotonous. We get it- we've got Records Management Analysts on our team who did this in their previous lives!
3. End User-Dependent, but No Value
Okay, hear us out. We are not saying metadata capture isn’t important, we’ve already stated that it is fundamental to properly manage and access your records. However, team members in Finance, Operations or other departments may not see the immediate value in manually capturing their metadata because they were not hired for this purpose and have other priorities. Thus, this task is more likely to get left on the back burner.
4. Unreliable
This is a recipe for inconsistency. Even if every end user is filling out the required metadata fields, this manual task leaves room for human error as, once again, users may not remember every naming convention or make mistakes after having to repeatedly capture information. Inconsistent capture = unreliable search.
5. Risks Non-Compliance (audit failure, fines and more)
Analysis has proven that relying on manual input = non-compliance. The above reasons map out why: when metadata is not properly captured, information is not consistently searchable in case of an audit or litigation case. This can put organizations at serious risk that records managers are trying to avoid.
What’s the alternative? Technology has helped us mitigate these gaps, no question about it. I have been in the industry long enough to see a slow and steady transition away from manual tasks, and an increased faith in technology.
Common technologies (and why they may still leave a gap)
Many solutions out there have paved the way and to them: thank you! However, with every waking morning, technology doesn't (and shouldn't) stay stagnant. It progresses, as it is there to keep up with our ever-changing landscape - think of the amount of data we are producing daily as an example (2.5 quintillion bytes of data, according to Forbes). And with it, processes must also change to remain current.
The COVID-19 pandemic has prompted a massive increase of remote work. For this remote work, the standard of many organizations using on-premise ECMs has now changed rapidly to platforms that allow for collaboration. For example, Microsoft has seen an increase of M365 deployments worldwide, backed with the promise that SharePoint was the Document Control tool we all had been waiting for.
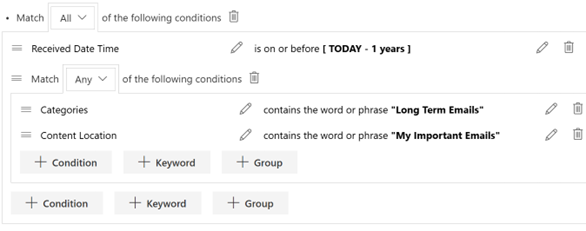
Recently, I participated in a demonstration for an add-on solution from a government agency showcasing how they manage their records within SharePoint. The technology that they were using was "cutting edge" but was still extremely end user-dependent: it required end users to manually capture a document's Content Type, as well as an assortment of metadata, so it could be properly declared, categorized and processed. And as can be seen in the screenshot below, SharePoint often requires manual metadata input as well.
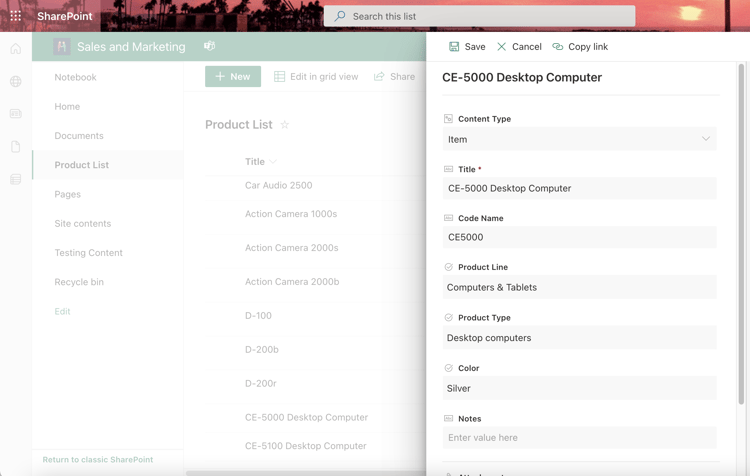
We are very happy that their solution works for them, and we celebrate their success. However, given the breadth and speed of data being produced, if this technique has not changed within new technologies, then it still gets in the way of productivity. End users and knowledge workers are already quite busy, so we believe implemented technology solutions should provide them with more time to focus on their jobs rather than requiring completion of additional records management tasks.
After all, if the end user does not ADOPT the system, it fails
Our proposed solution: intelligent technology that automates
Fear not, there is hope. Technology has come a long way! While we understand Information Governance and Architecture in SharePoint has evolved but may still leave gaps, we also know that there are now different approaches available with other technology. So, our solution to this particular problem is to select tools that offer features which automate metadata capture and other records management tasks. This way, we can rely on automation through features such as Content and Document Enrichment and Auto-categorization, just for starters.
Thus, our users are relied on very little, if at all.
Why? Because with the right tools, Content Types and other metadata no longer needs to be captured by humans. Content enrichment is the process of applying modern content processing techniques such as machine learning, artificial intelligence, and language processing to automatically extract meaningful information from your documents.
With content and document enrichment, any word/value on a document is indexed and now a "metadata field" and thus can be searched upon, autocategorization can be performed by machine logic based on specific organizational and retention requirements, and once again, you do not need to rely on end users anymore (removing human error from your equation!). We’ve included a screen shot example of the metadata that has automatically been filled out for an employee Termination Letter in the cloud solution, Collabspace.
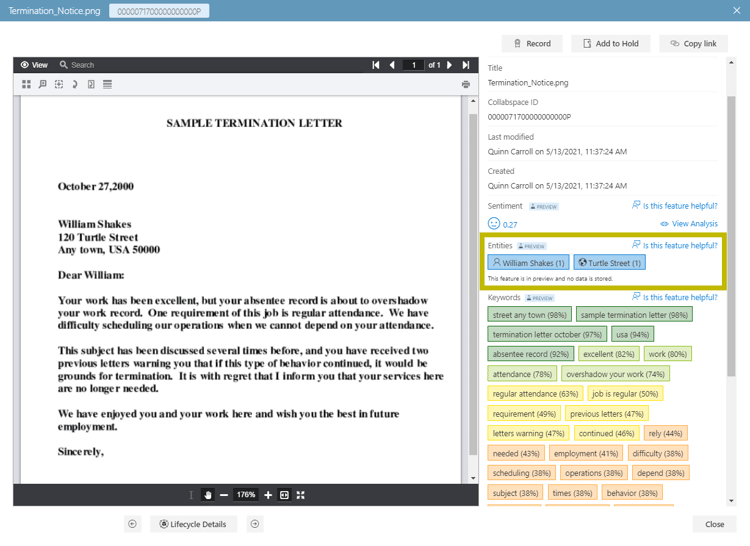
The result is a seamless experience for end users and RMs alike. A robust and transparent RM program, better customer service to your internal and external customers, increased productivity (now that end users’ time has been freed up), and overall, more value and savings across for your organization. Additionally, automated, compliant records management means risk aversion, and even if you are not in a highly-regulated industry – Legal will love you!
RM Transformation is here. I invite you to contact us at Collabware to see how our intelligent cloud solution, Collabspace, can be implemented to bring value to your organization. Download our full slide deck on this topic, below:


To learn more, we have also covered how to take advantage of automation with unstructured data intelligence in our whitepaper (free for download below). You can also read our articles about Collabspace features, such as Content Enrichment and Data Analytics.