Function versus Case Aggregates
A question that often comes up when determining how to implement Collabware CLM 2016 is how to leverage Aggregates and specifically how to organize the documents that make up that Aggregate. There are two approaches that are available, one being more common than the other: Functionally-organized content versus Case-organized content.
This article will break down both approaches, outline their pros and cons, and demonstrate how to achieve either option effectively. Before we do that, let’s set the stage with a clear example: Employee Files. We have already discussed why using Aggregates for Employee Files makes sense in other articles, but now we need to discuss the details of implementing this solution.
Employee Files are widely used and contain a variety of different documents created and used by a number of different working groups. Not only do Employee Files contain an employee’s recruitment documents, it also contains their compensation information, their contact and medical information, their employee relations documents, their benefits, as well as many others. Even though all of these different documents relate back to a single person, they could potentially be different document types and be used by different user groups. While Collabware CLM 2016’s Aggregates will help in both approaches, determining which is the best approach for your organization is a good discussion to have.
Function-based – The Traditional Way
The traditional way to manage employee documents, and most documents, is to create a location for each type of document and collect together every single instance of that document type. This would mean that a single SharePoint library might contain hundreds of records for different employees.
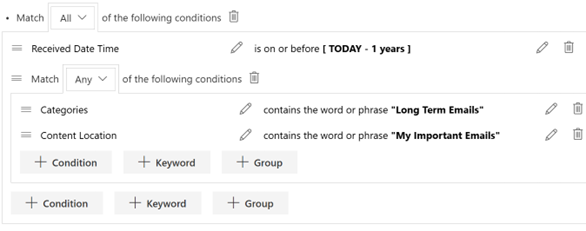
The main purpose of collecting together like documents is to establish some organization and security for that specific document type. Payroll documents and benefits documents might be created and managed by a branch of the Finance department, rather than HR. Employee Review documents might need to be locked down to a limited set of HR Managers. Keeping all of the same kind of documents together makes this easy to do, and also provides each working group a shared space to work within, regardless of which employee they are dealing with. The only difficult part with this approach is establishing retention across all of the different documents, which is where Aggregates come in. The goal here is to link each document to its appropriate Employee File, preferably in an automated way. This has to be repeated across any number of document libraries, depending on how this is organized. Eventually, once all the documents find themselves connected to an Employee File Aggregate, they can have things like retention and disposition applied. Let’s dig in to setting this up.
Before anything is started, we will almost always want a custom Content Type to support this. The function-based approach requires a custom Content Type, rather than just benefits from it like the case-based approach. The Content Type will be a simple collection of employee-related metadata values, with one key piece of metadata: Employee ID.
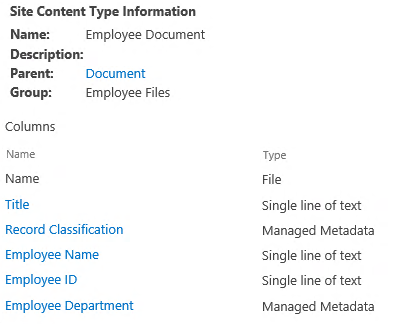
From this, we can create several different sub-Content Types, all inheriting from this base Employee Document. What we can also do is leverage these same metadata fields on our Aggregate Template, with a few extra for Human Resources purposes.
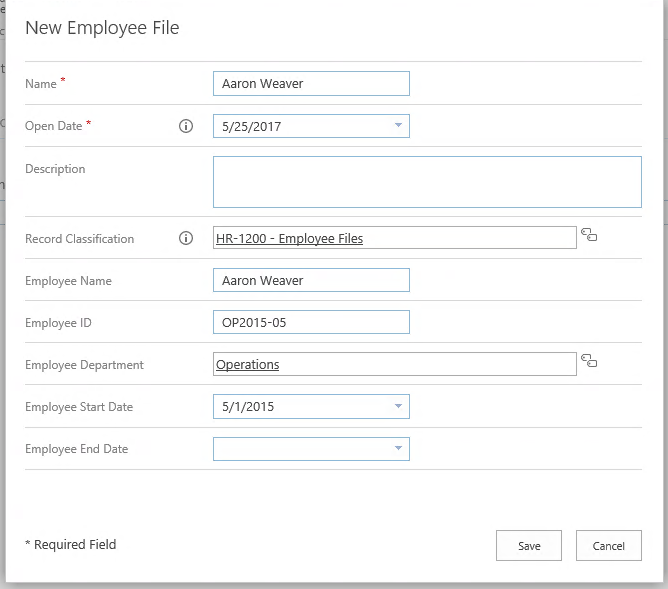
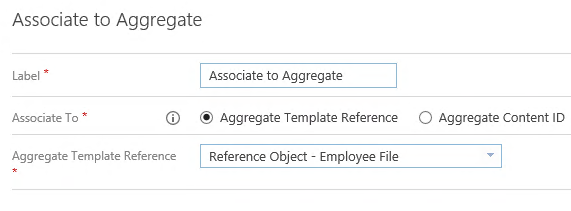
We now have both our main Content Type as well as our Employee File Aggregate. The next crucial piece to setting this up is to automate the association of documents to Aggregates. It would be far too manual to ask users to create that relationship every time, so we want to create a Content Rule and Workflow that can find and link up the items based on a shared piece of information. This is why we require a Content Type, and specifically, the Employee ID metadata field.
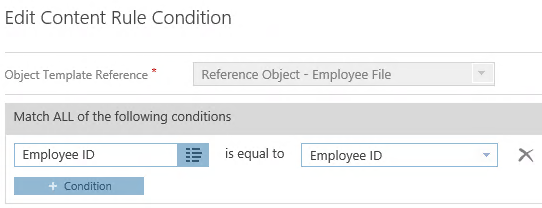
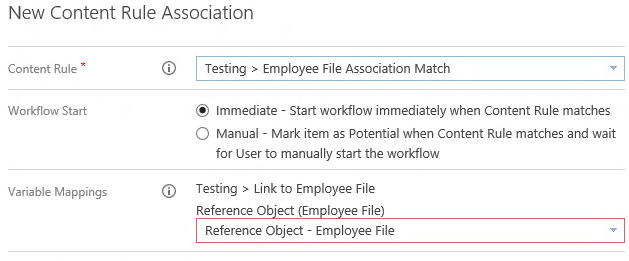
This kind of Content Rule is called a Reference Object Content Rule. Instead of relying on a static set of conditions to match content, we create the rule to compare the document’s metadata against a reference object, in this case our Employee File Aggregate, to find a matching instance based on a shared metadata value.
The next step in supporting this is to create a Workflow that can act on this information. The Workflow will be set up to expect not only a document to run on, but also an Employee File Aggregate as a reference object. This will allow us to tell the Workflow to automatically create the relationship so that our users don’t have to.
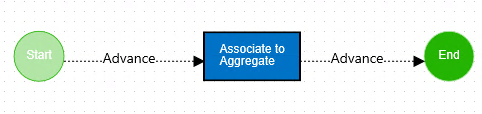
Finally, a Policy will link the Workflow and the Content Rule, and allow the Content Rule’s Reference Object to be mapped to the Workflow’s Reference Object.
This kind of setup allows Human Resource Employees to build up libraries around specific document types or business processes and have the association to an Employee File, and through that, record retention, automatically applied. Scan and Capture solutions can be very useful here, because they can simply be set to a specific location and documents can easily be uploaded. The only caveat here is that the user must know the correct Employee ID to enter; if they don’t know, or they make a typo, the Aggregate match will not happen, and the document might become orphaned.
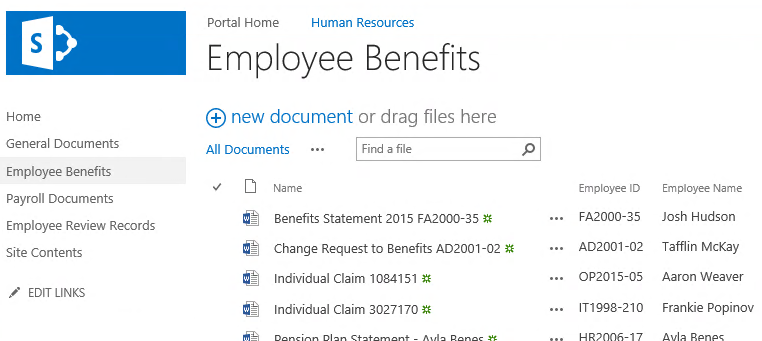
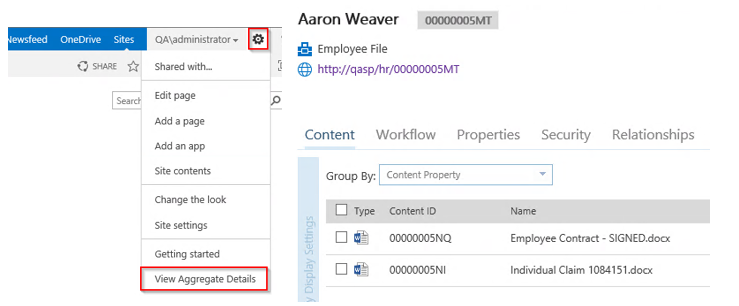
For example, this “Individual Claim” document has automatically been associated with Aaron Weaver’s Employee File because of the Employee ID match.
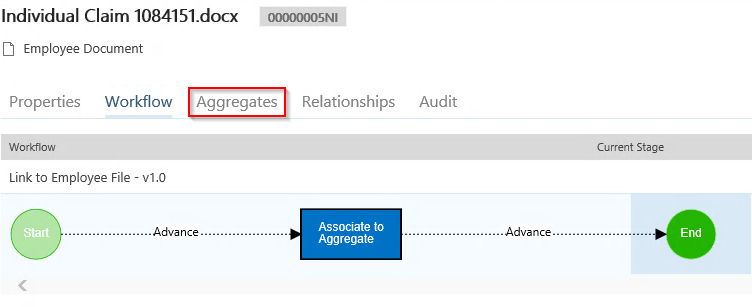
Any information specific to the Aggregate can be seen under the Aggregates tab, and the Human Resources user can always get back to the Aggregate from Lifecycle Details as well. Once the HR User is in the Aggregate Lifecycle Details, they will be able to see all associated documents across all sites and libraries, not just the documents in the library they were just in.
The major drawback of this approach is that it is might not be very user friendly regarding access, both for the individual employee and for the HR users. If the employee needs to get access to their individual records, then the Human Resources users either have to make a duplicate of the document (which would be going very far against the grain of information governance) or to manage documents security on an individual basis, a very complex beast to manage. Likewise, if the organization is large, these libraries could be filled with hundreds, even thousands of documents, making it difficult to sift through to find information related to a single person. An Information Query can be configured to allow users to see their content without having to use SharePoint Search, but this option still requires configuration.
So how do we address these access issues in a better way? This leads us to our second approach: employee-based.
Case-based – A Different Approach
The Case-based approach is exactly what it sounds like; all of the documents related to a single case, in this scenario, a single employee, are collected together in a single spot. This one location will have all of the information about that individual. It’s a one-stop-shop for both the HR users and the employee themselves, which resolves the issues of providing access, locating individual documents, and metadata can be shared across an entire location.
Luckily, setting this approach up is fairly simple. Some quick modifications to our existing Aggregate Template should get us most of the way there.
First of all, we need to configure our Aggregate Template to create a site for each instance; a site per employee file.
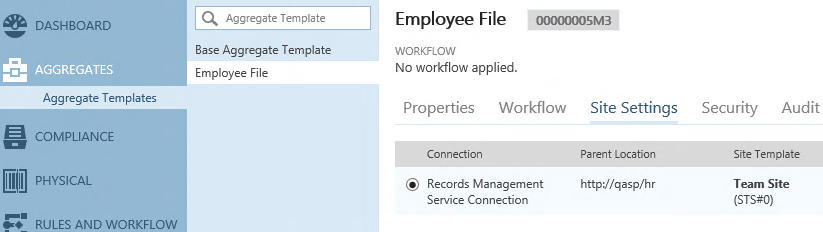
In this case, we’re just re-using existing structure, namely the Human Resources Site Collection. Each Employee File Site will be created as a subsite off our parent HR Site, so HR still maintains that level of control and access.
The next thing we want to do is configure our Aggregate to push down important metadata rather than asking our users to input that data themselves. The user has already navigated to the Employee’s site, why do they need to input metadata that can already been gathered from their location?
Since Aggregates have a metadata sharing feature, this is a fairly simple Column to Column mapping.
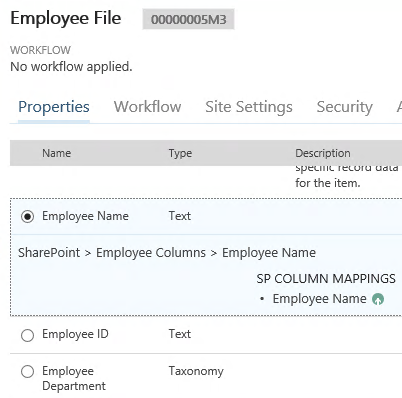
That’s about it for the setup; now every time an Aggregate is created, a Site will automatically be created for that Employee File.
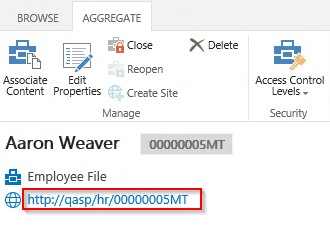
One of the major benefits of setting things up this way is that when documents are uploaded to the Employee File site, they are automatically associated with the Aggregate – no Content Rules or Workflows required. On top of this, if the Content Type on any of the document libraries of an Aggregate Site has the metadata fields mapped in the previous step, the Employee File’s metadata values will automatically be applied to the document upon upload.
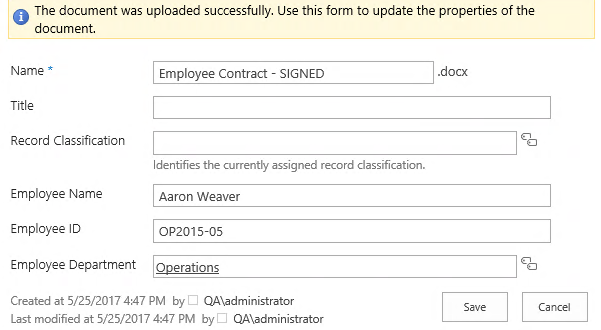
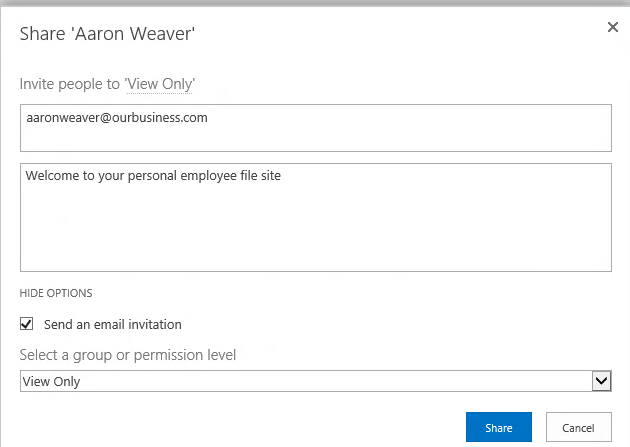
Finally, security is also much simpler here. If the employee needs access to their own records, simply give them View access to the site. There is no need for security management on individual documents, because the entire site is built for this user.
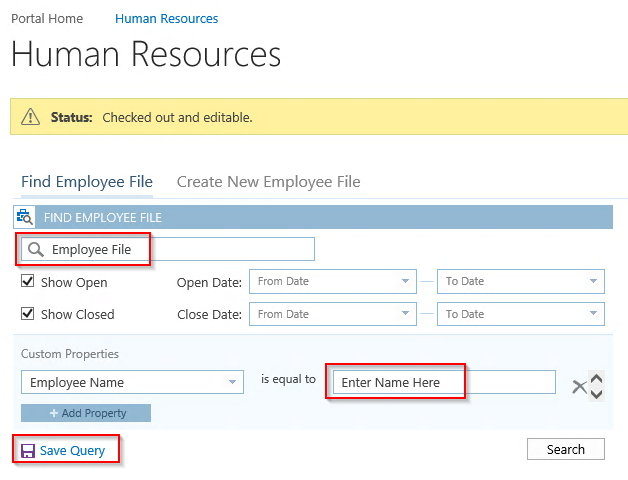
The main difficulty with this approach is that the HR users are required to do a few extra steps to locate an individual Employee File. Rather than just browsing to a shared library and dropping in the files, the HR user needs to first navigate to the Aggregate for that one employee. Likewise, a scan and capture solution would be require more steps to implement, because the documents need to be scanned to a drop-off location and then sent to the appropriate location by the SharePoint Content Organizer. It’s an additional step for the HR users and it requires thoughtful configuration.
The Aggregate Search Web Part can be used to make finding Employee File Aggregates simpler. It can be configured to only allow searching against Employee File Aggregates, and then the user just needs to know the name or the Employee ID.
It should also be mentioned that any confidential documents that shouldn’t be visible to the employee can easily be added to a different site and simply associated with the Aggregate. Within Aggregate Lifecycle Details, users will only be able to see those documents that they have permission to see, so there is no risk of information breaches.
In both scenarios, we would be applying retention and disposition to the Aggregate; this enables us to not only destroy the Aggregate and associated content, but also the Aggregate Site. This helps counter the dreaded SharePoint sprawl, because retention is being applied unilaterally to all entities associated with the Aggregate in a single disposition event.
Which approach is better?
When it comes to choosing the option that works best for your organization, it’s important to consider the existing structure in place. The function-based approach is more common by far, because it usually fits into an already existing system. Most users feel more comfortable with having a workspace that they use daily. If they are already confident with putting in specific metadata and sorting and filtering in those document libraries, then the function-based approach requires very little modification to what they already do.
The case-based approach is a great option for an organization that doesn’t have a thoroughly entrenched setup, and an organization that wants to provide employees access to their own files in a simple way. It’s ideal for larger organizations that require a more extreme approach to managing their content, due to volume or complexity. It’s simpler to set up and requires less input from the users, since much of the information can be auto-populated based on location alone.
As always, organizations should be encouraged to examine their current SharePoint implementation, their users, and their business processes before they decide on one approach over another. Collabware CLM 2016 is very flexible and can be used in many ways, but one option will usually fit better than another.
For more information on managing employee files or consultation on recommended options for your organization, please contact us.
For more details on how Collabware enhances SharePoint for complete and compliant records management features, feel free to entire download the Collabware CLM brochure:![]()